






























































Ngành trí tuệ nhân tạo ngày càng sử dụng dữ liệu tổng hợp, nhưng liệu đây có phải là con đường bền vững?
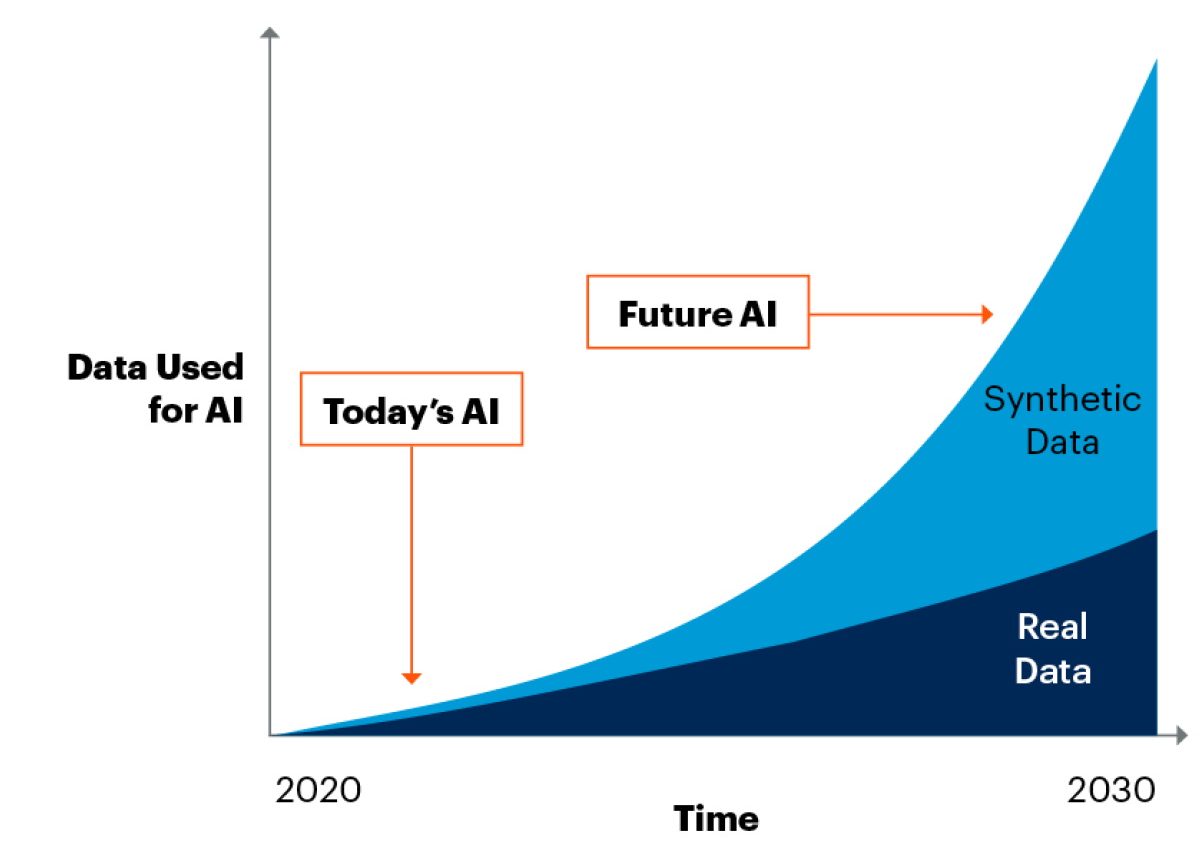
Hiện tại, nhiều trang web đã chặn các công cụ thu thập dữ liệu của các công ty AI. Theo Epoch AI, nếu xu hướng này tiếp diễn, dữ liệu huấn luyện AI có thể cạn kiệt trong khoảng từ 2026 đến 2032. Trong bối cảnh đó, các công ty trí tuệ nhân tạo (AI) như Anthropic, Meta và OpenAI đã bắt đầu sử dụng dữ liệu tổng hợp để đào tạo các mô hình của mình, như Claude 3.5 Sonnet, Llama 3.1 và Orion.
Việc này không chỉ giúp giảm chi phí và thời gian thu thập dữ liệu mà còn mở rộng khả năng tạo ra các bộ dữ liệu phong phú mà không phụ thuộc vào dữ liệu thực tế. Dữ liệu tổng hợp đóng vai trò quan trọng trong việc huấn luyện AI, đặc biệt trong việc gắn nhãn dữ liệu, một yếu tố then chốt giúp các mô hình nhận diện và dự đoán chính xác hơn.
Thị trường dữ liệu tổng hợp dự kiến đạt 2,34 tỷ USD vào năm 2030, và Gartner dự đoán 60% dữ liệu được sử dụng cho AI và phân tích trong năm nay sẽ được tạo tổng hợp. Tuy nhiên, việc phụ thuộc quá nhiều vào dữ liệu tổng hợp cũng mang lại những thách thức về chất lượng và tính đa dạng của dữ liệu.
Các nghiên cứu từ Đại học Rice và Stanford cho thấy mô hình AI có thể mất dần chất lượng và sự đa dạng nếu chỉ dựa vào dữ liệu tổng hợp. Ngoài ra, ngành công nghiệp AI cũng đối mặt với vấn đề thiên lệch dữ liệu khi dữ liệu tổng hợp có thể phản ánh những hạn chế và thiên lệch của dữ liệu gốc. Các mô hình được đào tạo trên dữ liệu có lỗi sẽ tạo ra dữ liệu có nhiều lỗi hơn, tạo thành một vòng lặp phản hồi tiêu cực.

Luca Soldaini, một nhà khoa học nghiên cứu cấp cao tại Viện AI Allen, cho rằng dữ liệu tổng hợp “thô” không đáng tin cậy. Việc sử dụng chúng một cách an toàn đòi hỏi phải xem xét, sắp xếp và lọc kỹ lưỡng, và lý tưởng nhất là kết hợp nó với dữ liệu thực tế mới.
Tuy nhiên, để khai thác tối đa lợi ích từ dữ liệu tổng hợp, ngành công nghệ cần tiếp tục nghiên cứu và phát triển các phương pháp đảm bảo chất lượng dữ liệu, đồng thời giải quyết các vấn đề về nhân lực để đạt được sự phát triển bền vững.
Mặc dù CEO OpenAI, Sam Altman, từng dự đoán AI sẽ tự tạo ra dữ liệu tổng hợp đủ tốt để tự huấn luyện, nhưng công nghệ này vẫn chưa xuất hiện. Ngành công nghệ cần cân bằng giữa lợi ích và rủi ro để tối ưu hóa tiềm năng của AI trong tương lai.

















































































































{kind=link}