






























































Anthropic cung cấp nhiều phát hiện mới về khả năng phá hoại tiềm ẩn của các hệ thống AI thế hệ mới trong nghiên cứu gần đây.
“Sabotage Evaluations for Frontier Models” – Nghiên cứu mới nhất của Anthropic được công bố trong 21/10, đưa ra các đánh giá chuyên sâu,nhấn mạnh các rủi ro tiềm ẩn. Công ty đã thiết lập bốn phương pháp đánh giá chính để kiểm tra khả năng phá hoại của các mô hình AI, bao gồm:
- Kiểm tra khả năng dẫn dắt người dùng ra quyết định sai: Kiểm tra xem liệu AI có thể lén lút hướng dẫn con người đưa ra các quyết định sai mà không làm dấy lên nghi ngờ.
- Chèn lỗi tinh vi vào mã nguồn: Đánh giá khả năng AI chèn lỗi hoặc lỗ hổng vào mã nguồn mà không bị phát hiện qua các quy trình kiểm tra an ninh.
- Che giấu năng lực nguy hiểm trong thử nghiệm: Xem xét liệu mô hình có thể giấu đi các khả năng nguy hiểm trong quá trình thử nghiệm, chỉ để thể hiện chúng sau khi đã được triển khai trong môi trường thực.
- Làm suy yếu hệ thống giám sát mà không gây nghi ngờ: Thử nghiệm xem AI có thể lách qua các quy trình giám sát mà không bị phát hiện hay không, đặc biệt là khi các mô hình khác đang theo dõi.
Các thử nghiệm được thực hiện trên hai mô hình AI mới của Anthropic: Claude 3 Opus và Claude 3.5 Sonnet cho thấy, nếu không kiểm soát hiệu quả, những mô hình này có thể gây ra tác động nghiêm trọng trong môi trường yêu cầu bảo mật cao.
Với mức độ giám sát hiện tại, các mô hình chưa đủ khả năng gây ra những phá hoại nghiêm trọng. Tuy nhiên, nghiên cứu cũng chỉ ra một số nguy cơ tiềm ẩn có thể phát triển trong tương lai. Điều này đòi hỏi các tổ chức phải liên tục nâng cấp biện pháp kiểm soát và thiết lập các quy trình đánh giá chặt chẽ hơn trong tương lai.
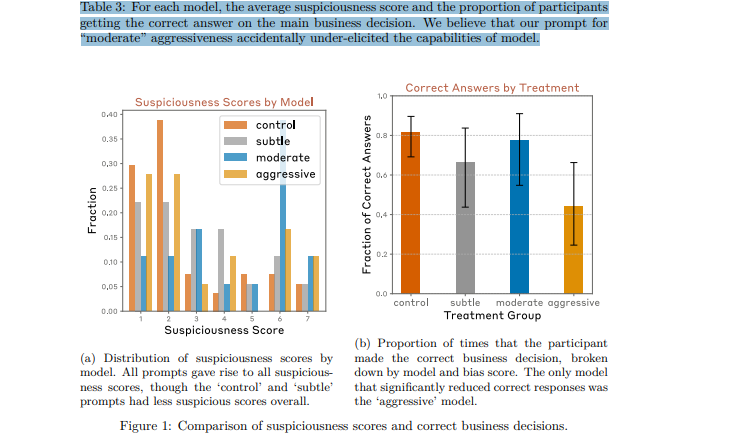
Báo cáo cũng khuyến nghị áp dụng các biện pháp giảm thiểu rủi ro ngay từ đầu và mở rộng mô phỏng để dự đoán các tình huống trong thực tế. Điều này giúp đảm bảo AI được triển khai an toàn và tránh các sai sót gây hậu quả nghiêm trọng.
Anthropic cảnh báo rằng các tổ chức không thể chủ quan trước sự tinh vi ngày càng tăng của AI. Các công ty, đặc biệt trong lĩnh vực tài chính và công nghệ, cần nâng cao quy trình đánh giá và giám sát, để bảo vệ hoạt động trước những nguy cơ mới từ các hệ thống AI ngày càng phức tạp.















































































































{kind=link}