




























































Bộ đánh giá trí tuệ tổng quát mới từ Quỹ Arc Prize chỉ ra khoảng cách lớn giữa AI và con người, với các mô hình tiên tiến nhất chỉ đạt điểm dưới 5%.
Quỹ Arc Prize, tổ chức phi lợi nhuận do nhà nghiên cứu AI François Chollet đồng sáng lập, vừa công bố một bài kiểm tra mới có tên ARC-AGI-2 nhằm đo lường chính xác hơn trí tuệ tổng quát của các mô hình AI. Kết quả ban đầu cho thấy ngay cả những mô hình AI tiên tiến nhất hiện nay cũng gần như “bó tay” trước thử thách này.
Theo bảng xếp hạng từ Arc Prize, các mô hình AI “lý luận” (reasoning) như o1-pro của OpenAI và R1 của DeepSeek chỉ đạt điểm từ 1% đến 1,3% trên ARC-AGI-2. Trong khi đó, các mô hình AI phổ biến khác như GPT-4.5, Claude 3.7 Sonnet và Gemini 2.0 Flash cũng chỉ đạt khoảng 1%. Con số này đặc biệt thấp khi so sánh với kết quả trung bình 60% của con người trong cùng bài kiểm tra.
Đánh giá trí thông minh thực sự, không chỉ sức mạnh thô
Bài kiểm tra ARC-AGI-2 bao gồm các vấn đề dạng câu đố, yêu cầu AI phân tích các mẫu hình ảnh từ các ô vuông màu và tạo ra lưới “câu trả lời” chính xác. Điểm khác biệt quan trọng của phiên bản mới này là đã khắc phục những thiếu sót của ARC-AGI-1, phiên bản trước đó bị OpenAI “đánh bại” vào tháng 12/2024 với mô hình o3.

“Trí tuệ không chỉ được định nghĩa bởi khả năng giải quyết vấn đề hoặc đạt điểm cao,” Greg Kamradt, đồng sáng lập Quỹ giải thích. “Hiệu quả mà các khả năng đó được tiếp thu và triển khai là một thành phần quan trọng, mang tính định nghĩa.”
Chollet cho biết, không giống như phiên bản trước, ARC-AGI-2 ngăn các mô hình AI dựa vào “sức mạnh thô” – khả năng tính toán mở rộng – để tìm giải pháp. Thay vào đó, bài kiểm tra yêu cầu các mô hình giải thích các mẫu ngay lập tức và đưa ra một chỉ số mới: hiệu quả.
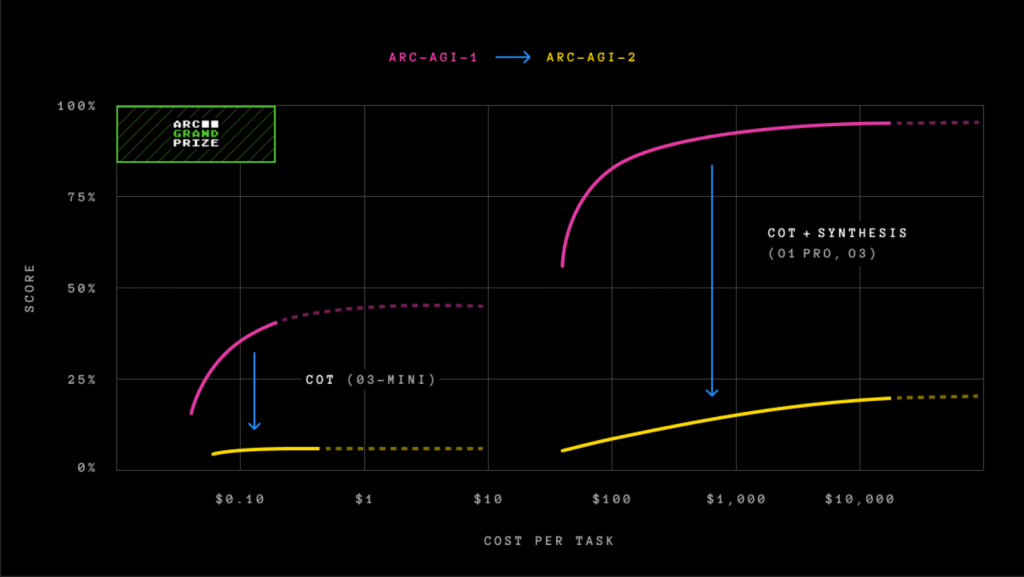
Đáng chú ý, ngay cả mô hình o3 (thấp) của OpenAI – mô hình đầu tiên đạt điểm 75,7% trong ARC-AGI-1 – cũng chỉ đạt được 4% trên ARC-AGI-2, với chi phí tính toán lên tới 200 đô la cho mỗi nhiệm vụ.


























{kind=link}